This is an article about a new tool in our project: the library jsoup. I want to describe the problem jsoup solves for us and the arguments why jsoup is the right library to solve this problem.
Motivation
As in other applications, our users can input text via HTML editor. Often, they copy-paste content from several sources such as Microsoft Office. Hence, a lot of obscure, malformed and incomplete HTML with proprietary tags is thrown at our application.
This causes problems when doing a fulltext search over these texts. This search covers every word the user types in the mentioned editors. Because the user can copy-paste HTML, using the original input texts would also use the HTML tags and attributes. Because the user isn’t aware that he pastes a whole lot more than just the text he can read, we first have to remove the HTML. Then we append the resulting plain texts to get one large string that contains every word the user entered. This text is stored at the database and gets searched by the fulltext search. This approach performs pretty well and is easy to implement.
And here’s the problem: To remove the HTML, we use the old Swing ParseDelegator. Recently, I discovered a bug in this approach. Removing HTML from the following string:
<ul>
<li>Listitem 1</li>
<li>Listitem 2</li>
</ul>Results in this string:
„Listitem 1Listitem 2“As I said before, we use the resulting string for a full text search. A search for “1Listitem” would match the search despite of the visible input text never includes this string. Hence, we need a new way of removing HTML.
Options
1. Regex
Removing HTML from a text using regular expressions is a bad idea. There’s a good article about that topic. The short version is this: HTML is a recursive structure whereas Regex are not able to parse recursively. I really am not that much into both HTML and Regex so I cannot prove the article wrong or true. However a lot of articles I found basically agree to Regex not being the right approach to remove HTML from a string.
2. apache.tika
Apache Tika parses content from various documents and is already present in our codebase. However, I was not able to get the simplest examples for removing HTML to run.
3. SAXParser
The SAXParser is an XML-parser in the JDK. However, it is not an HTML parser so it’s not the best solution to deal with HTML: It throws a SAXParseException if confronted with malformed HTML.
4. jsoup
We finally ended up using this library. In the next chapter, I want to describe why.
Our Choice: Jsoup
jsoup is a HTML parser that makes sense of “real-world HTML soup”. It provides a lot of cool features like
- Parsing and traversing documents
- Parse a document from a string
- Use DOM methods to navigate a document
- Sanitize untrusted HTML to prevent XSS
There’s also a nice online demo:
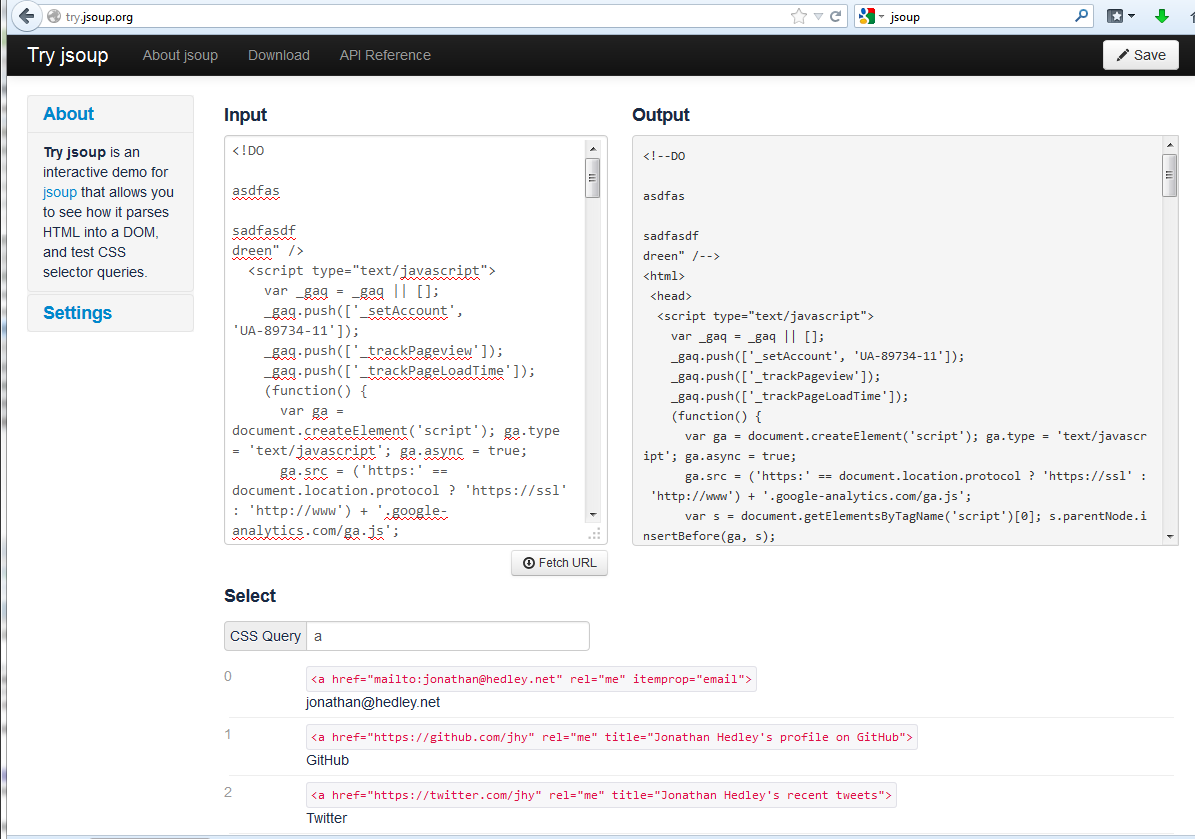
As you can see in the screenshot, I kind of messed up the HTML on the left. Despite the wrong header, the missing head-section and the missing body-tag, jsoup apparently was able to parse the HTML document.
As I want to do for every new library we add in the future, I wrote some tests for jsoup. These tests make sure that jsoup behaves as we expect for our typical “trouble makers”:
import static org.junit.Assert.assertEquals;
import org.jsoup.Jsoup;
import org.junit.Test;
/**
* This class tests jsoup. jsoup is a library that can work with HTML-Strings.
*
* @author Steven Schwenke
* @since 29.10.2014
*/
public class JsoupTest {
/**
* With other solutions, elements of lists have been appended without a space between them.
*/
@Test
public void beimParsenVonPlaintextWerdenLeerzeichenZwischenListenelementenEingefuegt() {
String einfacheListe = "<ul><li>erstes Listitem</li><li>zweites Listitem</li></ul>" //
+ "<ol><li>erstes Listitem</li><li>zweites Listitem</li></ol>";
String plainText = Jsoup.parse(einfacheListe).text();
assertEquals("erstes Listitem zweites Listitem erstes Listitem zweites Listitem", plainText);
}
/**
* Umlaut should be masked when removing HTML-tags.
*/
@Test
public void beimParsenVonPlaintextWerdenUmlauteWerdenDemaskiert() {
String wortMitUmlaut = "Lösungen";
String plainText = Jsoup.parse(wortMitUmlaut).text();
assertEquals("Lösungen", plainText);
}
/**
* Faulty HTML should be parsed, too, when removing HTML-tags.
*/
@Test
public void beimParsenVonPlaintextWirdMalformedHTMLTrotzdemGeparsed() {
String kaputtesHTML = "<html><body>Hallo </p></body></html>";
String plainText = Jsoup.parse(kaputtesHTML).text();
assertEquals("Hallo", plainText);
}
/**
* Incomplete HTML should be parsed, too, when removing HTML tags.
*/
@Test
public void beimParsenVonPlaintextKannhtmlFragementGeparsedWerden() {
String kaputtesHTML = "Hallo<h1>Überschrift</h1>";
String plainText = Jsoup.parse(kaputtesHTML).text();
assertEquals("Hallo Überschrift", plainText);
}
/**
* Copy-paste from MS Office applications brings proprietary tags and
* attributes that should be removed when removing HTML from a string.
*/
@Test
public void beimParsenVonPlaintextWerdenMicrosoftTagsGefiltert() {
String hTMLMitMicrosoftTags = "<html xmlns:m=\"http://schemas.microsoft.com/office/2004/12/omml\" xmlns=\"http://www.w3.org/TR/REC-html40\"><o:\\w+>Hallo</o:\\w+><h1 class=\"MsoNormal\">Überschrift</h1>";
String plainText = Jsoup.parse(hTMLMitMicrosoftTags).text();
assertEquals("Hallo Überschrift", plainText);
}
}Also very important for us when adding a new library to our code base is that this library is actively developed and supported. That seems to be the case with jsoup:
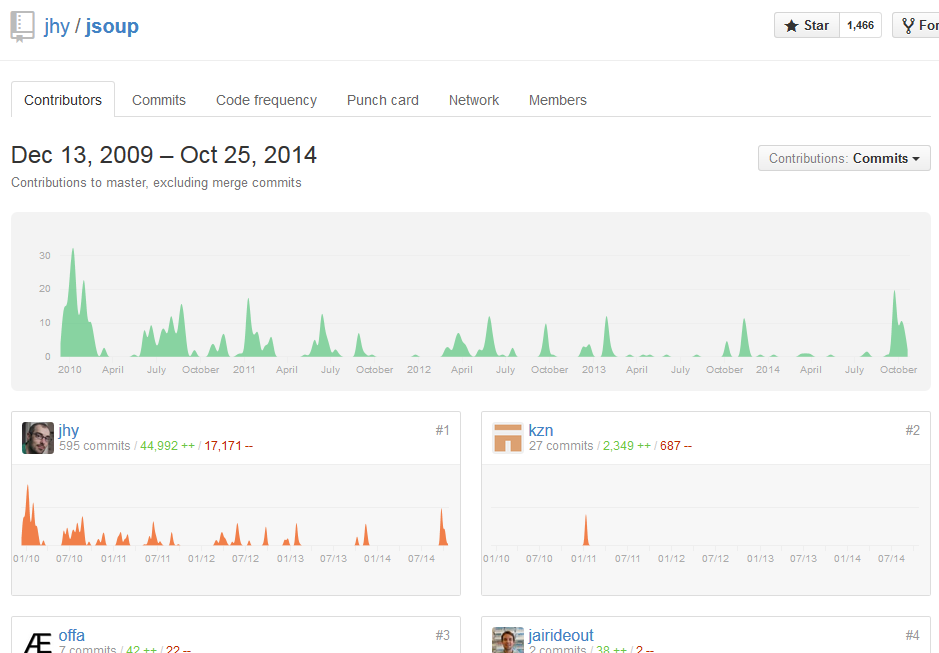
Also, we can use the library commercially because it’s under MIT licence. A nice bonus is that jsoup has no dependencies.
TL;DR
Don’t use Regex to remove HTML from Strings! Jsoup is a small and alive library that can do that far better.